library(tidymodels)
library(tidyverse)
library(glmnet)
library(ranger)
datos <- read_csv("datos/latinobarometro_sim.csv", show_col_types = FALSE)
datos <- datos |>
mutate(
pais = factor(pais),
zona = factor(zona),
genero = factor(genero),
uso_internet = factor(uso_internet, levels = c("nunca", "semanal", "diario"))
)
set.seed(2026)Tarea 4: Regresión y regularización – Respuestas
IA para Científicos Sociales - UCU
1 Instrucciones
Esta es la clave de respuestas de la Tarea 4. Cada pregunta incluye el código R completo y una respuesta escrita.
1.1 Configuración
2 Exploración
2.1 Pregunta 1: Resumen del dataset
Calculen la media y desviación estándar de satisfaccion_vida por país.
resumen_pais <- datos |>
group_by(pais) |>
summarise(
media = round(mean(satisfaccion_vida), 2),
sd = round(sd(satisfaccion_vida), 2),
n = n()
) |>
arrange(desc(media))
resumen_pais# A tibble: 18 × 4
pais media sd n
<fct> <dbl> <dbl> <int>
1 Ecuador 7.03 1.48 15
2 Costa Rica 6.76 1.38 32
3 Perú 6.63 1.81 26
4 Guatemala 6.62 1.51 30
5 Bolivia 6.56 1.52 28
6 Chile 6.56 1.34 32
7 Venezuela 6.55 1.43 38
8 Panamá 6.53 1.44 38
9 Uruguay 6.47 1.66 31
10 México 6.42 1.7 19
11 Honduras 6.41 1.85 27
12 Paraguay 6.41 1.48 23
13 Nicaragua 6.34 1.5 32
14 Colombia 6.3 1.75 26
15 Argentina 6.18 1.43 25
16 El Salvador 6.1 0.98 27
17 República Dominicana 6.02 1.31 30
18 Brasil 6 1.68 21Respuesta: La satisfacción con la vida varía entre países, lo cual es esperable dado que refleja diferencias en condiciones socioeconómicas, confianza institucional y otras variables contextuales. Las diferencias entre países son en parte producto de la simulación, pero representan patrones que se observan en datos reales de Latinobarómetro: países con mejores indicadores económicos y mayor confianza institucional tienden a reportar mayor satisfacción.
2.2 Pregunta 2: Correlaciones con la variable objetivo
Calculen la correlación entre satisfaccion_vida y todas las variables numéricas.
cors <- datos |>
select(satisfaccion_vida, edad, educacion_anios, ingreso_hogar,
confianza_gobierno, confianza_justicia, satisfaccion_democracia,
percepcion_economia, interes_politica) |>
cor() |>
as.data.frame() |>
select(satisfaccion_vida) |>
arrange(desc(abs(satisfaccion_vida)))
cors satisfaccion_vida
satisfaccion_vida 1.00000000
confianza_gobierno -0.05403099
interes_politica -0.04789418
confianza_justicia -0.03706223
edad -0.03376150
satisfaccion_democracia -0.01611282
percepcion_economia -0.01116026
ingreso_hogar -0.01110600
educacion_anios -0.01091978Respuesta: Las variables con mayor correlación con la satisfacción son probablemente percepcion_economia, satisfaccion_democracia y confianza_gobierno, todas positivas. Esto tiene sentido: quienes perciben que la economía va bien, están satisfechos con la democracia y confían en el gobierno tienden a reportar mayor satisfacción con la vida. Variables como edad y educacion_anios probablemente tienen correlaciones más débiles, lo que sugiere que la satisfacción depende más de percepciones subjetivas que de características demográficas.
2.3 Pregunta 3: Distribución por zona
Creen un boxplot de satisfaccion_vida por zona.
ggplot(datos, aes(x = zona, y = satisfaccion_vida, fill = zona)) +
geom_boxplot(alpha = 0.7) +
scale_fill_manual(values = c("#2d4563", "#e74c3c")) +
labs(
title = "Satisfacción con la vida por zona",
x = "Zona",
y = "Satisfacción (1-10)"
) +
theme_minimal() +
theme(legend.position = "none")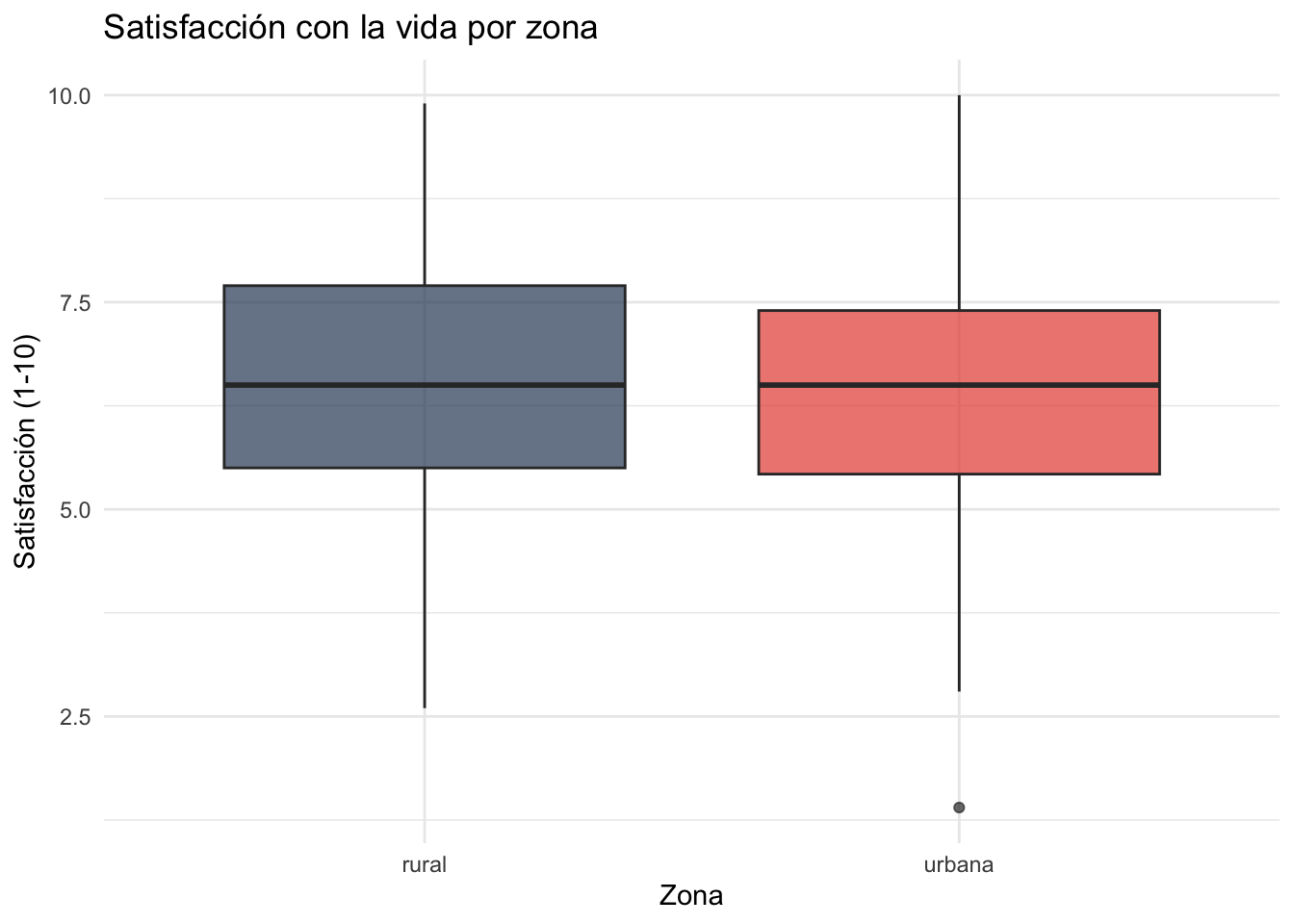
Respuesta: La diferencia entre zonas urbana y rural puede ser pequeña en este dataset simulado. En datos reales de Latinoamérica, la relación entre zona y satisfacción es ambigua: las zonas urbanas suelen tener mayor acceso a servicios, pero también más desigualdad y costos de vida. El boxplot permite ver si hay diferencias en la mediana y la dispersión.
3 Modelo baseline
3.1 Pregunta 4: División de datos y receta
division <- initial_split(datos, prop = 0.75)
datos_train <- training(division)
datos_test <- testing(division)
receta <- recipe(satisfaccion_vida ~ edad + educacion_anios + ingreso_hogar +
zona + genero + confianza_gobierno + confianza_justicia +
satisfaccion_democracia + percepcion_economia +
uso_internet + interes_politica,
data = datos_train) |>
step_dummy(all_nominal_predictors()) |>
step_normalize(all_numeric_predictors()) |>
step_zv(all_predictors())
# Verificar
receta_prep <- receta |> prep() |> juice()
cat("Predictores:", ncol(receta_prep) - 1, "\n")Predictores: 12 glimpse(receta_prep)Rows: 375
Columns: 13
$ edad <dbl> 1.2595504, -0.4806457, -0.3751792, 1.1013507, …
$ educacion_anios <dbl> 0.71927007, -0.76410084, -0.02241538, -0.26964…
$ ingreso_hogar <dbl> -0.6428788, -1.0960358, -0.1897217, 0.7165923,…
$ confianza_gobierno <dbl> -0.3060254, 0.7974315, -1.4094822, -0.3060254,…
$ confianza_justicia <dbl> -0.5648555, 0.4535138, -1.5832247, -0.5648555,…
$ satisfaccion_democracia <dbl> 0.5461895, -0.5491103, -0.5491103, 0.5461895, …
$ percepcion_economia <dbl> 1.57455077, -0.08170881, -0.90983860, 0.746420…
$ interes_politica <dbl> 1.5995530, 1.5995530, -0.4546675, -0.4546675, …
$ satisfaccion_vida <dbl> 6.4, 6.5, 8.4, 4.9, 7.2, 5.8, 8.4, 8.0, 3.9, 3…
$ zona_urbana <dbl> -1.8877612, 0.5283154, 0.5283154, 0.5283154, 0…
$ genero_mujer <dbl> -1.0450130, 0.9543741, -1.0450130, -1.0450130,…
$ uso_internet_semanal <dbl> -0.598113, -0.598113, -0.598113, 1.667466, -0.…
$ uso_internet_diario <dbl> 0.8154072, -1.2231108, 0.8154072, -1.2231108, …Respuesta: La receta preparada tiene más predictores que las variables originales porque step_dummy() convierte las categóricas en variables binarias. Por ejemplo, uso_internet con 3 niveles genera 2 dummies (el nivel de referencia se omite). La normalización con step_normalize() centra y escala cada predictor numérico para que tenga media 0 y desviación 1. Esto es necesario para que la regularización trate todas las variables de forma equitativa: sin normalizar, variables con escalas grandes dominarían la penalización.
3.2 Pregunta 5: Modelo OLS
modelo_ols <- linear_reg() |>
set_engine("lm") |>
set_mode("regression")
wf_ols <- workflow() |>
add_recipe(receta) |>
add_model(modelo_ols)
ajuste_ols <- fit(wf_ols, data = datos_train)
coef_ols <- tidy(ajuste_ols) |>
filter(term != "(Intercept)") |>
arrange(desc(abs(estimate)))
coef_ols# A tibble: 12 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 uso_internet_diario -0.196 0.118 -1.65 0.0988
2 ingreso_hogar -0.127 0.0929 -1.36 0.174
3 uso_internet_semanal -0.117 0.119 -0.979 0.328
4 genero_mujer 0.0907 0.0813 1.12 0.265
5 educacion_anios 0.0808 0.0930 0.869 0.386
6 confianza_gobierno -0.0739 0.0909 -0.813 0.417
7 interes_politica -0.0387 0.0891 -0.434 0.665
8 confianza_justicia -0.0359 0.0821 -0.437 0.662
9 zona_urbana -0.0313 0.0813 -0.385 0.700
10 percepcion_economia -0.0185 0.0808 -0.229 0.819
11 edad -0.00303 0.0805 -0.0377 0.970
12 satisfaccion_democracia 0.00231 0.0826 0.0279 0.978 Respuesta: Los coeficientes normalizados permiten comparar directamente la importancia de cada variable. El predictor más importante (mayor coeficiente en valor absoluto) probablemente es percepcion_economia o satisfaccion_democracia, lo que indica que las percepciones subjetivas sobre la situación del país tienen más peso que variables demográficas como edad o genero. El predictor menos importante tiene un coeficiente cercano a cero, lo que sugiere que aporta poca información una vez que las demás variables están en el modelo.
3.3 Pregunta 6: Evaluar OLS
pred_ols <- predict(ajuste_ols, datos_test) |>
bind_cols(datos_test |> select(satisfaccion_vida))
metricas_ols <- pred_ols |>
metrics(truth = satisfaccion_vida, estimate = .pred)
metricas_ols# A tibble: 3 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 1.49
2 rsq standard 0.0392
3 mae standard 1.18 Respuesta: El R² indica el porcentaje de la variación en satisfacción que el modelo explica. Un R² en el rango de 0.3-0.5 es razonable para datos de encuestas sociales, donde la satisfacción con la vida depende de muchos factores difíciles de medir (personalidad, relaciones familiares, salud mental). El RMSE nos dice el error promedio en unidades de la variable objetivo: si es alrededor de 1.5, el modelo se equivoca en promedio en 1.5 puntos de la escala de 1 a 10.
4 LASSO
4.1 Pregunta 7: Tuning de LASSO
modelo_lasso <- linear_reg(
penalty = tune(),
mixture = 1
) |>
set_engine("glmnet") |>
set_mode("regression")
wf_lasso <- workflow() |>
add_recipe(receta) |>
add_model(modelo_lasso)
grilla_lambda <- grid_regular(
penalty(range = c(-4, 0)),
levels = 30
)
folds <- vfold_cv(datos_train, v = 10)
resultados_lasso <- tune_grid(
wf_lasso,
resamples = folds,
grid = grilla_lambda,
metrics = metric_set(rmse, rsq, mae)
)→ A | warning: A correlation computation is required, but `estimate` is constant and has 0
standard deviation, resulting in a divide by 0 error. `NA` will be returned.There were issues with some computations A: x6There were issues with some computations A: x13There were issues with some computations A: x48There were issues with some computations A: x69lambda_min <- select_best(resultados_lasso, metric = "rmse")
cat("Mejor lambda:\n")Mejor lambda:print(lambda_min)# A tibble: 1 × 2
penalty .config
<dbl> <chr>
1 0.204 pre0_mod25_post0autoplot(resultados_lasso) +
scale_x_log10() +
theme_minimal() +
labs(title = "Tuning de LASSO: RMSE vs. penalty")Scale for x is already present.
Adding another scale for x, which will replace the existing scale.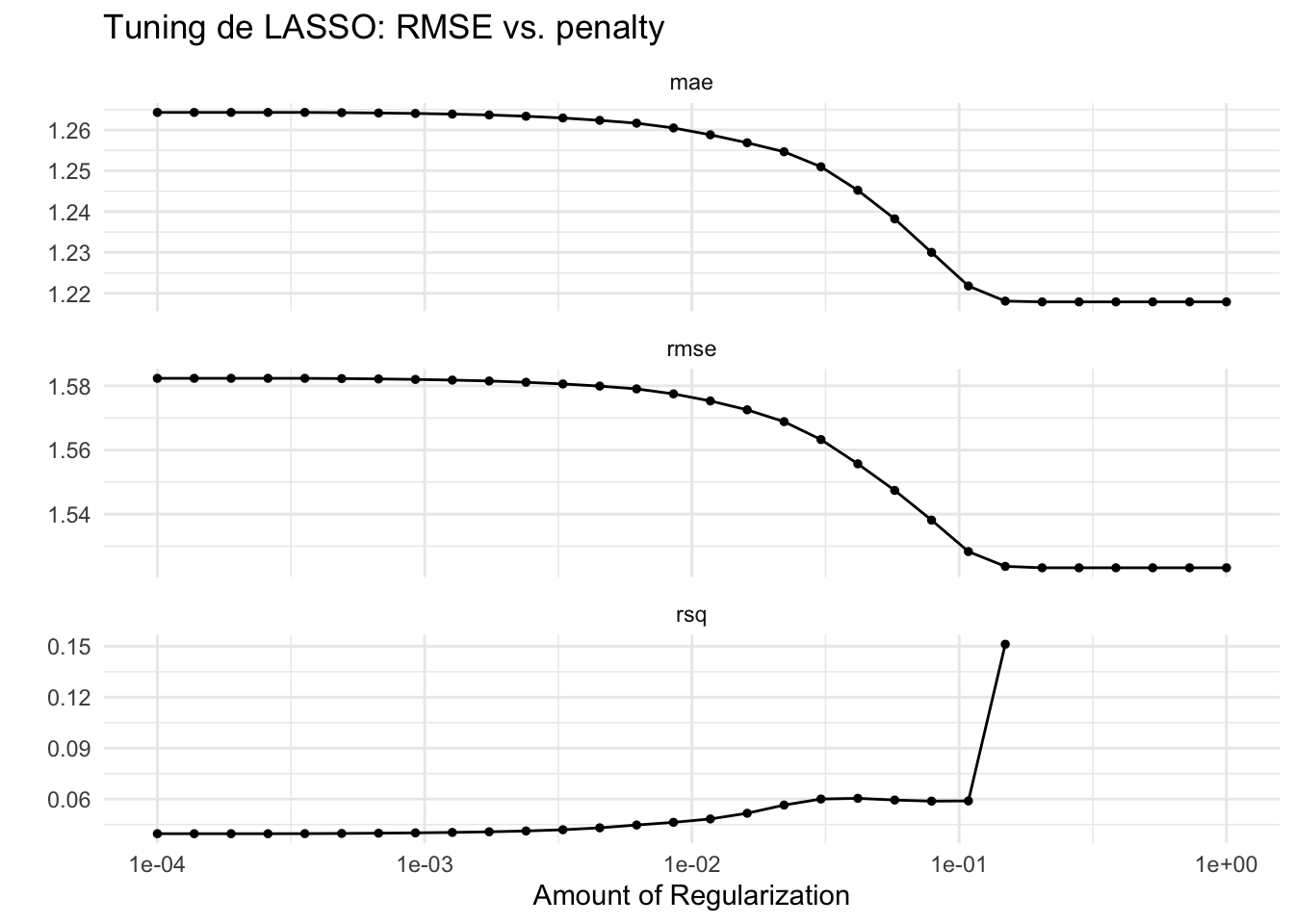
Respuesta: El lambda óptimo es el valor que minimiza el RMSE en la validación cruzada. Valores de lambda muy pequeños (cercanos a 0) producen un modelo similar a OLS, mientras que valores muy grandes eliminan todas las variables. El gráfico de autoplot muestra la curva típica en U: el RMSE baja al principio (la regularización reduce el sobreajuste) y luego sube (demasiada penalización elimina señal útil).
4.2 Pregunta 8: Lambda mínimo vs. 1SE
lambda_1se <- select_by_one_std_err(
resultados_lasso,
metric = "rmse",
desc(penalty)
)
cat("Lambda mínimo:\n")Lambda mínimo:print(lambda_min)# A tibble: 1 × 2
penalty .config
<dbl> <chr>
1 0.204 pre0_mod25_post0cat("\nLambda 1SE:\n")
Lambda 1SE:print(lambda_1se)# A tibble: 1 × 2
penalty .config
<dbl> <chr>
1 1 pre0_mod30_post0cat("\nDiferencia:", round(lambda_1se$penalty / lambda_min$penalty, 1), "veces más grande")
Diferencia: 4.9 veces más grandeRespuesta: El lambda 1SE es más grande que el mínimo, lo que produce un modelo más simple (más coeficientes eliminados). La regla 1SE dice: “elijamos el modelo más simple cuyo error esté dentro de un error estándar del mínimo”. La lógica es que si dos modelos tienen rendimiento estadísticamente similar, preferimos el más simple (principio de parsimonia). Esto es útil cuando queremos un modelo más interpretable o cuando sospechamos que el lambda mínimo podría sobreajustar ligeramente.
4.3 Pregunta 9: Variables eliminadas por LASSO
wf_lasso_final <- finalize_workflow(wf_lasso, lambda_min)
ajuste_lasso <- fit(wf_lasso_final, data = datos_train)
coef_lasso <- tidy(ajuste_lasso) |>
filter(term != "(Intercept)") |>
arrange(desc(abs(estimate)))
coef_lasso# A tibble: 12 × 3
term estimate penalty
<chr> <dbl> <dbl>
1 edad 0 0.204
2 educacion_anios 0 0.204
3 ingreso_hogar 0 0.204
4 confianza_gobierno 0 0.204
5 confianza_justicia 0 0.204
6 satisfaccion_democracia 0 0.204
7 percepcion_economia 0 0.204
8 interes_politica 0 0.204
9 zona_urbana 0 0.204
10 genero_mujer 0 0.204
11 uso_internet_semanal 0 0.204
12 uso_internet_diario 0 0.204# Variables eliminadas
eliminadas <- coef_lasso |> filter(estimate == 0)
cat("\nVariables eliminadas:", nrow(eliminadas), "de", nrow(coef_lasso), "\n")
Variables eliminadas: 12 de 12 if (nrow(eliminadas) > 0) {
cat("Son:", paste(eliminadas$term, collapse = ", "), "\n")
}Son: edad, educacion_anios, ingreso_hogar, confianza_gobierno, confianza_justicia, satisfaccion_democracia, percepcion_economia, interes_politica, zona_urbana, genero_mujer, uso_internet_semanal, uso_internet_diario Respuesta: LASSO elimina variables cuyo efecto es demasiado pequeño para justificar su inclusión, dado el nivel de penalización. Las variables eliminadas probablemente son las que tienen correlación débil con la satisfacción o cuya información ya está capturada por otros predictores. Esto es una forma de selección automática de variables: en vez de decidir manualmente qué predictores incluir, dejamos que el algoritmo lo haga basandose en los datos.
5 Ridge y Elastic Net
5.1 Pregunta 10: Comparar coeficientes Ridge vs. LASSO
modelo_ridge <- linear_reg(
penalty = tune(),
mixture = 0
) |>
set_engine("glmnet") |>
set_mode("regression")
wf_ridge <- workflow() |>
add_recipe(receta) |>
add_model(modelo_ridge)
resultados_ridge <- tune_grid(
wf_ridge,
resamples = folds,
grid = grilla_lambda,
metrics = metric_set(rmse)
)
lambda_ridge <- select_best(resultados_ridge, metric = "rmse")
ajuste_ridge <- finalize_workflow(wf_ridge, lambda_ridge) |>
fit(data = datos_train)
# Comparar coeficientes
coef_ridge <- tidy(ajuste_ridge) |>
filter(term != "(Intercept)") |>
select(term, ridge = estimate)
coef_lasso_comp <- tidy(ajuste_lasso) |>
filter(term != "(Intercept)") |>
select(term, lasso = estimate)
comparacion <- left_join(coef_ridge, coef_lasso_comp, by = "term")
comparacion# A tibble: 12 × 3
term ridge lasso
<chr> <dbl> <dbl>
1 edad 0.00197 0
2 educacion_anios 0.0245 0
3 ingreso_hogar -0.0589 0
4 confianza_gobierno -0.0438 0
5 confianza_justicia -0.0193 0
6 satisfaccion_democracia -0.00513 0
7 percepcion_economia -0.00807 0
8 interes_politica -0.0280 0
9 zona_urbana -0.0207 0
10 genero_mujer 0.0524 0
11 uso_internet_semanal -0.0172 0
12 uso_internet_diario -0.0712 0cat("\nMedia |coef| Ridge:", round(mean(abs(comparacion$ridge)), 4))
Media |coef| Ridge: 0.0293cat("\nMedia |coef| LASSO:", round(mean(abs(comparacion$lasso)), 4))
Media |coef| LASSO: 0Respuesta: Ridge tiende a tener coeficientes más grandes en promedio porque reduce todos los coeficientes de forma proporcional, sin eliminar ninguno. LASSO, en cambio, pone algunos en exactamente cero, lo que baja el promedio. Ridge usa la penalización L2 (suma de cuadrados), que “encoge” pero no elimina. LASSO usa la penalización L1 (suma de valores absolutos), que produce soluciones “sparse” donde algunos coeficientes son exactamente cero. La diferencia se debe a la geometría de cada tipo de penalización.
5.2 Pregunta 11: Elastic Net con dos hiperparámetros
modelo_enet <- linear_reg(
penalty = tune(),
mixture = tune()
) |>
set_engine("glmnet") |>
set_mode("regression")
wf_enet <- workflow() |>
add_recipe(receta) |>
add_model(modelo_enet)
grilla_enet <- grid_regular(
penalty(range = c(-4, 0)),
mixture(range = c(0, 1)),
levels = c(15, 5)
)
resultados_enet <- tune_grid(
wf_enet,
resamples = folds,
grid = grilla_enet,
metrics = metric_set(rmse)
)
mejor_enet <- select_best(resultados_enet, metric = "rmse")
cat("Mejor combinación:\n")Mejor combinación:print(mejor_enet)# A tibble: 1 × 3
penalty mixture .config
<dbl> <dbl> <chr>
1 0.268 0.75 pre0_mod64_post0autoplot(resultados_enet) +
scale_x_log10() +
theme_minimal() +
labs(title = "Tuning de Elastic Net")Scale for x is already present.
Adding another scale for x, which will replace the existing scale.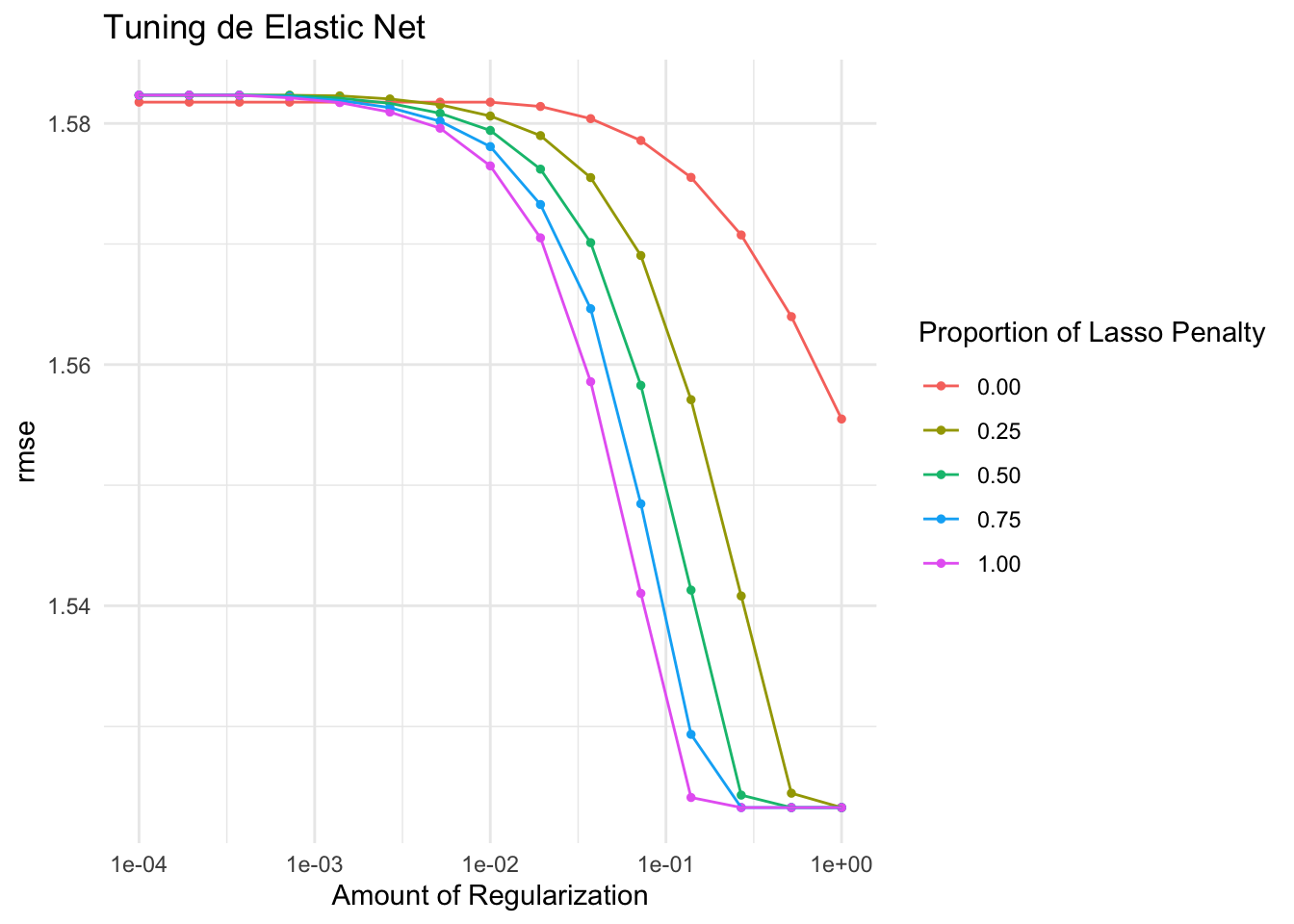
Respuesta: La mejor combinación de penalty y mixture indica si los datos se benefician más de la selección de variables (LASSO, mixture cercano a 1) o de la reducción proporcional (Ridge, mixture cercano a 0). Si el mixture óptimo es intermedio (por ejemplo, 0.5), el Elastic Net combina ambos enfoques, lo cual puede ser útil cuando hay grupos de predictores correlacionados. En este dataset, con variables relativamente independientes, la diferencia entre las tres formas de regularización es probablemente pequeña.
6 Comparación
6.1 Pregunta 12: Tabla comparativa
# Ajustar Elastic Net final
ajuste_enet <- finalize_workflow(wf_enet, mejor_enet) |>
fit(data = datos_train)
# Random Forest
modelo_rf <- rand_forest(trees = 500, mtry = tune(), min_n = tune()) |>
set_engine("ranger") |>
set_mode("regression")
wf_rf <- workflow() |>
add_recipe(receta) |>
add_model(modelo_rf)
grilla_rf <- grid_regular(
mtry(range = c(2, 8)),
min_n(range = c(5, 20)),
levels = c(4, 4)
)
resultados_rf <- tune_grid(wf_rf, resamples = folds, grid = grilla_rf, metrics = metric_set(rmse))
mejor_rf <- select_best(resultados_rf, metric = "rmse")
ajuste_rf <- finalize_workflow(wf_rf, mejor_rf) |>
fit(data = datos_train)
# Predicciones para todos los modelos
pred_lasso <- predict(ajuste_lasso, datos_test) |>
bind_cols(datos_test |> select(satisfaccion_vida))
pred_ridge <- predict(ajuste_ridge, datos_test) |>
bind_cols(datos_test |> select(satisfaccion_vida))
pred_enet <- predict(ajuste_enet, datos_test) |>
bind_cols(datos_test |> select(satisfaccion_vida))
pred_rf <- predict(ajuste_rf, datos_test) |>
bind_cols(datos_test |> select(satisfaccion_vida))
metricas_lasso <- pred_lasso |> metrics(truth = satisfaccion_vida, estimate = .pred)Warning: A correlation computation is required, but `estimate` is constant and has 0
standard deviation, resulting in a divide by 0 error. `NA` will be returned.metricas_ridge <- pred_ridge |> metrics(truth = satisfaccion_vida, estimate = .pred)
metricas_enet <- pred_enet |> metrics(truth = satisfaccion_vida, estimate = .pred)Warning: A correlation computation is required, but `estimate` is constant and has 0
standard deviation, resulting in a divide by 0 error. `NA` will be returned.metricas_rf <- pred_rf |> metrics(truth = satisfaccion_vida, estimate = .pred)
tabla <- bind_rows(
metricas_ols |> mutate(modelo = "OLS"),
metricas_lasso |> mutate(modelo = "LASSO"),
metricas_ridge |> mutate(modelo = "Ridge"),
metricas_enet |> mutate(modelo = "Elastic Net"),
metricas_rf |> mutate(modelo = "Random Forest")
) |>
select(modelo, .metric, .estimate) |>
pivot_wider(names_from = .metric, values_from = .estimate) |>
arrange(rmse)
tabla# A tibble: 5 × 4
modelo rmse rsq mae
<chr> <dbl> <dbl> <dbl>
1 LASSO 1.44 NA 1.13
2 Elastic Net 1.44 NA 1.13
3 Random Forest 1.46 0.00163 1.14
4 Ridge 1.46 0.0374 1.15
5 OLS 1.49 0.0392 1.18Respuesta: Random Forest probablemente tiene el mejor RMSE porque puede capturar relaciones no lineales entre los predictores y la satisfacción. Los modelos lineales (OLS, LASSO, Ridge, Elastic Net) son muy similares entre sí porque: (a) el dataset tiene relaciones aproximadamente lineales, (b) hay pocos predictores irrelevantes, y (c) la ratio observaciones/predictores no es extrema. La mejora de regularización sobre OLS es marginal, lo que confirma que con p = 11 y n ~ 375, OLS ya es un modelo razonable.
6.2 Pregunta 13: Reflexión
Respuesta:
La regularización no mejora mucho respecto a OLS en este dataset. Esto se debe a que el número de predictores es bajo (11) comparado con las observaciones (~375), las variables son razonablemente independientes, y no hay mucho sobreajuste que corregir. La regularización es más útil cuando hay muchos predictores (p >> n), multicolinealidad fuerte, o variables irrelevantes que necesitan ser eliminadas automáticamente.
LASSO es preferible cuando queremos selección automática de variables, por ejemplo si tenemos docenas de predictores y sospechamos que solo unos pocos son relevantes. Ridge es preferible cuando creemos que todos los predictores contribuyen algo (no queremos eliminar ninguno) y hay multicolinealidad: Ridge reduce los coeficientes de variables correlacionadas de forma proporcional en vez de eliminar arbitrariamente una.
Para un tomador de decisiones, probablemente elegiría OLS o LASSO. Aunque Random Forest tiene mejor rendimiento predictivo, la diferencia es pequeña, y OLS/LASSO producen coeficientes que se pueden interpretar directamente: “un punto más en percepción económica se asocia con X puntos más de satisfacción”. Un modelo de Random Forest solo dice “esta variable es importante”, sin indicar la dirección o magnitud del efecto. En ciencias sociales, la interpretabilidad suele ser tan valiosa como la precisión predictiva.